MessagePack for C# v2, new era of .NET Core(Unity) I/O Pipelines
MessagePack for C# Version 2 was released in 2019–12–16. The main implementation was done by Andrew Arnott who is a software engineer at Microsoft, Visual Studio Team. I checked the API design and performance and took care of the Unity compatibility. This collaboration took almost a year, and I think we did a great job.
https://github.com/neuecc/MessagePack-CSharp
Version 1 that implemented by me greatly boosted the old serializer’s performance standards and set a new standard. Version 2 made it work with new APIs (Span, System.Buffers) and also the overall I/O pipeline was optimized upon deciding how the serializer should be. For the C# application architecture henceforth, it will be an important thing.
There are many breaking changes, but the guide for migrating from Version 1 to Version 2 is in migration.md.
MessagePack for C# is used in ASP.NET Core(existing in the submodule in the repository!) and Visual Studio 2019.
Zero copy with pipeline
When thinking of the internal structure of MessagePack for C#, there are the following two method signatures to be looked at:
void Serialize<T>(IBufferWriter<byte> writer, T value)
T Deserialize<T>(in ReadOnlySequence<byte> byteSequence)
The changes made after Version 1 are that for the serialization, IBufferWriter<byte> is to be used for the I/O, and for deserialization, ReadOnlySequence<byte> is to be used for the I/O. Both are .NET Standard 2.1 generation interfaces defined in System.Buffers. Whereas in Version 1, both were byte[] based.

The I/O pipeline handles the process from the input to the application processing and from the application processing to the output. At the end, when it goes to the native layer, most of it becomes byte[]. For C#, the most primitive type (SocketAsyncEventArgs, ConslePal+Stream, FileStream, etc.) bridging the native layer is handled by the framework layer, and the serializer result is output. It is important to look at this process flow.
The serializer is always at the core(Object -> byte[] conversion, byte[] -> Object conversion). The image above is a normal case for example the RedisValue (StackExchange.Redis) takes byte[] and ByteArrayContent (HttpClient) takes byte[]. In many cases, they take raw byte[]. In such cases, the serializer will return a new byte[] result, which will be processed by the framework and again copied to the I/O source.
The overhead occurring here is the allocation as well as the copying of byte[].

Therefore, as a way to avoid the allocation of byte[], the serializer uses an external buffer pool (with .NET Core 3.0, the ArrayPool<byte> defined by System.Buffers is used a lot even in the class library) as the operation area, and it writes to the Stream provided by the framework.
By doing so, the required cost will only be for copying. Note that although it is theoretically possible to write directly to the Stream so the buffer will not be used, the large Write overhead will degrade the performance. Also, the Stream may have a buffer internally in either case. The design idea behind Version 1 was based on byte[] to avoid this large overhead and deem a single serialization result as the buffer area, so that without any overhead, the serialization would be executed and the writing to Stream could be done all at once. That was our idea. The respective architecture policy was correct, and we eliminated the performance of various serializers existing at the time.

When IBufferWriter<byte> is used, the buffer required for the operation can be directly requested to the original source. This enables the buffer to be completely managed by the original source. And so this eliminates the copy cost from the operating buffer in the serializer. For example, SocketAsyncEventArgs used for socket communications is normally used, but it is possible to directly write to its own (byte[] Buffer).
For the Stream, PipeWriter provided by System.IO.Pipelines implements IBufferWriter<byte> and optimally manages the buffer as a substitute.
From ASP.NET Core 3.0, in addition to the traditional (Stream HttpResponse.Body), (PipeWriter HttpResponse.BodyWriter) is also now provided. Officially provided by MessagePack for C# Version 2, MessagePack.AspNetCoreMvcFormatter provides a serialized implementation for BodyWriter in the case of .NETCoreApp 3.0.
The current .NET framework mostly either requests Stream or byte[], or ArraySegment(ReadOnlyMemory). However, when IBufferWriter is supported at the framework level, the true value of MessagePack for C# Version 2 will likely be apparent. Of course, even with API(byte[] Serialize<T>(T value)) that returns byte[], optimum buffer management suppresses the allocation and copy cost.
Theory and performance
It is often misunderstood that just using Span will increase the performance, using async/await will increase the performance.
The current performance with .NET Core is based on the idea of “The buffer should be managed well, the execution should be in synchronous, and await should be minimized.” The double while loop shown in Introduction to System.Threading.Channels is an example of this.
while (await channelReader.WaitToReadAsync())
while (channelReader.TryRead(out T item))
Use(item);Even with the serializer, since many object operations and binary processing are executed, it is necessary for the processing to be completed in sync as much as possible.
In Version 1, we defined one unit of buffer as the serialization of one type and the processes were executed according to this rule. This implementation works “correctly” from the aspect of performance. The fact is, Version 1 had less processing overhead than Version 2. Therefore, if you look at the performance of just one operation, it may be faster than with Version 2.
In particular, if IBufferWriter<byte> or ReadOnlySequence<byte> is simply implemented, it will not be faster. Logically, even if the copy is reduced, it may become slower. If the request (GetSpan/Memory + Advance) for the IBufferWriter writing area or the ReadOnlySequence<byte>’s Slice is simply used, it can slow down the performance.
To avoid this slowdown in performance, it will be necessary to carefully create an intermediate layer that suitably manages the buffer obtained with IBufferWriter<byte> and to create an intermediate layer that suitably manages the Segment buffer obtained with ReadOnlySequence<byte>.
Version 2 implements these adequately and successfully minimize degraded performance by using Version 1’s standard as the benchmark to detect the performance being degraded by the presence of the intermediate layers, where Version 1 is fine-tuned to the limit in terms of writing to a simple buffer.
If you compare Version 1 and Version 2, Version 2 comes out on top as the actual application. By integrating the pipeline mentioned above and implementing various measures for smarter buffer management, Version 2 is better when we think about it overall.
LZ4 compression for the array
One factor in Version 2’s performance improvement over Version 1 was the new allocation where Version 1 did not use a pool for 64K or higher serialization. For the internal buffer, Version 2 uses the 32K chunk’s linked list obtained from the ArrayPool (in the case where IBufferWriter is not given externally and Version 2’s internal buffer pool is used).
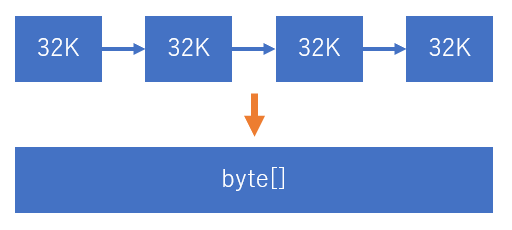
When creating byte[], it is connected in the end in one clump. When writing to Stream, there is WriteAsync for every 32K. If this floods the buffer, instead of securing a buffer twice the size as with List<T> and writing to it, the size of the buffer used will always be less than 85K, so we can also avoid consuming the Large Object Heap (LOH).
As for MessagePackCompression.Lz4BlockArray, which is a new compression mode newly provided by Version 2, this internal format is used to apply LZ4 compression to every 32K.

Since it is compressed, it avoids having in advance a large array that has become a clump of everything. During serialization also, memory efficiency is effective. However, for deserialization, since decompression can be done in blocks, it is advantageous because even the large data need not have a huge array.
The compression mode used in Version 1 is still available as MessagePackCompression.Lz4Block. However, with Version 2, using MessagePackCompression.Lz4BlockArray is recommended. As for the binary data already compressed, Lz4Block can be deserialized even with Lz4BlockArray (same for vice versa).
AOT (Unity IL2CPP, Xamarin, UWP, CoreRT)
Since MessagePack for C# is geared for performance, it has no fallback to an easy reflection in the AOT environment and we have no desire to implement one. Instead, by generating the code in advance, the fastest serialization is achieved whenever possible in the AOT environment. From Version 2, .NET Core Tools, MSBuild Task, and Unity Editor Window have been provided for easier handling. It is now easier to use than ever before.
Since I founded Cysharp, a company that builds games with Unity + .NET Core (a subsidiary of Cygames, I definitely had to enable compatibility with Unity.
Conclusion
Much of the wonderful work was done by Andrew Arnott. I thank him again.
We will make MessagePack for C# Version 2 the heart of the .NET application henceforth. (Since it is always at the core of pipeline!) But as mentioned above, on the framework level, we still largely have not finished making it compatible with IBufferWriter, etc.
I am also creating an RPC framework called MagicOnion based on HTTP/2 and gRPC(Without requiring .proto, this RPC can be completed with only C#. It is better replaceable from WCF.). Due to the situation of the dependent library, there are many stages that resort to byte[] and this becomes a problem for performance as well. This is a serious problem especially since we are developing games with realtime communication in mind with Unity. I’ll replace the network layer in MagicOnion in the next update to solve it.
Also, MessagePack for C# Version 1, ZeroFormatter which I had developed earlier and Utf8Json, I am proud that I revamped the standards for high-speed serializers.
This Version 2 will also likely establish new standards. I would be very happy if it becomes a library that sparks debate over what the .NET Core 3 serializers should be.
With regard to Utf8Json, we want to improve it as we did for Version 2. Unfortunately, the JsonSerializer performance is extremely poor with System.Text.Json implemented officially by Microsoft and first appearing in .NET Core 3.
So Utf8Json is still necessary. Too bad that Microsoft does not know at all how to create a flexible and good performing serializer. I understand this so I should be able to create one without a problem.
The entire .NET is also complete with Core 3 fundamental tools for performance. However, revisions of libraries and frameworks are still ahead. Many remain close to byte[] bases. And especially since ADO.NET is a very old and thick layer, which requires a faster and thinner new abstraction layer.
When everything is in place, C# will be the fastest and best environment for truly realistic applications. I also want to contribute to that.